JavaSE
[TOC]
JavaSE
基础
八种基本数据类型
final关键字
final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变。
重写重载
重载:发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
重写:重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
为什么在重写 equals 方法的时候需要重写 hashCode 方法
hashCode() 方法返回对象的散列码,而 equals() 方法用于比较两个对象是否相等
重写 equals() 方法时,我们通常会根据对象的属性或状态来比较两个对象是否相等。如果两个对象相等,那么它们的 hashCode() 方法应该返回相同的值。
String、StringBuffer与StringBuilder的区别
范围:String对象是不可变的,而StringBuffer和StringBuilder是可变字符序列。每次对String的操作相当于生成一个新的String对象,而对StringBuffer和StringBuilder的操作是对对象本身的操作,而不会生成新的对象,所以对于频繁改变内容的字符串避免使用String,因为频繁的生成对象将会对系统性能产生影响。
线程安全:String由于有final修饰,是immutable的,安全性是简单而纯粹的。StringBuilder和StringBuffer的区别在于StringBuilder不保证同步,也就是说如果需要线程安全需要使用StringBuffer,不需要同步的StringBuilder效率更高。
集合类
Collection(集合)类
Set
TreeSet(logN):基于红黑树实现
HashSet(1):基于哈希表实现,支持快速,但不有序
LinkedHashSet(1):快速查找,并且内部使用双向链表保证有序
List
ArrayList:基于动态数组实现,随机访问
Vector:跟ArrayList比较多了线程安全
LinkedList:与双向链表实现,只能顺序访问
Queue
LinkedQueue:双向队列
PriorityQueue:优先队列,一般算法使用的比较多(最短路径,最大最小值的时候)
ArrayList自动扩容
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。
这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。
Map类
TreeMap:基于红黑树实现
HashMap:1.7基于哈希表实现,1.8过后基于数组+链表+红黑树实现
LinkedHashMap:使用双向链表来维护元素的顺序
1.8HashMap如何实现
在Java8中,当链表中的元素达到8个的时候,会将链表自动转换为红黑树(在这之前会先判断。如果当前数组的长度小于64,那么会先将数组扩容,再转换成红黑树),转换成红黑树的原因是减少搜索时间
HashMap和HashTable的区别
线程:HashMap不是线程安全的,HashTable是线程安全的(他的内部的方法基本上都经过synchronized修饰的)
效率:HashMap肯定效率高一点
数据结构:1.8过后HashMap是数组+链表+红黑树;HashTable底层是数组实现,每个数组元素都是一个链表或红黑树
HashMap为什么线程不安全
在1.8过后的HashMap中,多个键值对可能会被分配到同一个桶中。多个线程对HashMap的put操作会造成线程不安全
两个线程1 2 同时进行put操作,并且发生了哈希冲突
不同的线程可能在不同的时间片获得了CPU执行的机会,当前线程1执行完哈希冲突判断后,由于时间片消耗挂起。线程2先完成了插入
后面线程1获得了时间片,由于之前已经进行过hash碰撞的判断,所以此时会直接插入,这就导致线程2插入的数据被线程1给覆盖了
ConcurrentHashMap了解过吗
ConcurrentHashMap也是线程安全的,他和HashTable的实现线程安全的方式不同:
ConcurrentHashMap:使用Node数组+链表+红黑树的数据结构来实现,并发控制使用
synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,加锁是对node进行加锁,synchronized只锁定当前链表或红黑树的首节点,这样是要hash不冲突,就不会产生并发。就不会影响其他Node的读写,效率大福提升HashTable:使用
synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法的时候,其他线程也来访问同步方法。就可能会进入阻塞或轮询状态
并发JUC
线程进程
进程是程序的一个执行过程,是系统运行程序的基本单位,所以说进程是动态的。
线程和进程相似,线程是比进程更小的执行单位。一个进程在执行的过程中可以产生多个线程。
线程被称为轻量级进程:同类的多个线程是共享进程的堆和方法区的资源,但是每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之前之间切换工作的时候。负担要比进程小得多
线程的堆和方法区
堆和方法区是所有线程共享的资源。其中对是进程中最大的一块内存,只要用存放新创建的对象。方法区主要用于存放各一件被加载在的类信息、常量、静态常量、即时编译器编译后的代码等数据
说说线程的声明周期
线程有6中状态:new、runnable、blocked、waiting、time_waiting、terminaled
说说死锁
死锁就是,多个线程同时被阻塞,他们中的一个或者全部都在等待某个资源被释放。
比如说线程A持有资源2,线程2持有资源1,他们同时想得到对方的资源,这样就会卡死,死锁
死锁产生的条件
互斥:对于资源X和Y,只能被一个线程占用
占有且等待:假设一个线程A占用了X,然后A去申请Y,而在申请Y的过程中,A仍占用Y
不可抢占:假设线程A占有了共享资源X,则其他线程无法强制获得A占有的资源
循环等待:即线程A等待线程B占有的资源,而线程B又在等待线程A占有的资源
如何解决(避免)死锁
一次性申请所有的资源
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源
知道sleep()和wait()的区别吗
sleep()没有释放锁,wait()释放了锁的
wait()通常被用于线程之间交互/通信,sleep()通常被使用来暂停执行
sleep()是Thread的静态本地方法;wait()是Object类的本地方法
sleep()方法调用过后,可以自动苏醒;wait()方法需要其他线程notify通知才苏醒
volatile
volatile关键字能保证数据的可见性,有序性。但是不能保证数据的原子性
有序性
volatile关键字有个作用就是防止JVM的指令重排序,就如果我们将一个变量声明为volatile的话,在对这个变量进行读写操作的时候,会通过内存屏障的方式禁止指令重排
原子性(不保证)
因为一个变量进行++的时候(
inc++),他实际上是个符合操作:
读取
inc的值对
inc进行加1写回
inc而volatile无法保证这三个操作是在一个原子操作下
CAS
CAS(Campare And Swap),用于实现乐观锁。它的思想就是用一个预期值和要更新的变量值进行比较。两只相等才会进行更新。
在这个过程当中涉及到三个操作数:
V:要更新的变量值(Var)
E:预期值(Expected)
N:准备写入的值(New)
整个过程是当且仅当V==E的时候,CAS通过原子方式(CPU底层的原子指令)用N来更新V;如果不相等,就说明已经有其他线程更新了V了,当前线程放弃更新
CAS有什么缺点呢
CAS操作是通过空旋/自旋来进行重试的,如果没有成功更新的话,就会一直在那里空旋,时间长的话CPU负载爆满
ABA问题
ABA问题就是:如果一个变量V初次读取的时候是A,在准备赋值的时候我们检查V==E的结果,发现还是A,自认为正确。但是我们其实不能认为A没有被其他线程修改过。因为这个过程当中允许被改成了B而后又被改回了A。使得CAS操作就误认为它没有被修改过。
这就是所谓的ABA问题
如何处理ABA问题
解决思路就是,类似于乐观锁,在变量前面追加版本号或者时间戳
先判断当前值是否==预期值;
再判断当前标志是否-==预期标志
synchronized
它主要解决的是多个线程之间访问资源的同步性,可以保证被它修饰的方法或者代码块一直都是只有一个线程在执行
在Java6过后,synchronized引入了大量的优化:自旋锁,锁消除,锁粗化,偏向锁,轻量级锁等技术来减少锁的操作开销
synchronized底层实现
synchronized底层……那个好像要看class字节码文件,目前还没看过
synchronized和volatile的区别
这两个关键字是两个互补的存在
volatile关键字是线程同步的轻量级实现,所以volatile性能好得多volatile只能修饰变量;而synchronized可以修饰方法以及代码块volatile不能保证原子性volatile主要解决多个线程之间的可见性;synchronized关键字解决的是多个线程之间访问资源的同步性
Lock锁
ReentrantLock
ReentrantLock是实现了Lock接口的,可重入独占锁。
它和
synchronized类似,不过比它更灵活更强大,添加了轮询、超时、中断、公平锁、非公平锁等高级功能
ReentrantLock和synchronized的区别
底层依赖来说:
synchronized依赖于JVM实现,jdk6为synchronized做的优化都是在虚拟机层面的,没有直接暴露出来
ReentrantLock依赖于JDK层面实现,也就是API层面,他需要lock(),unlock(),try-catch-final来结合完成
ReentransLock相比synchronized的高级功能
等待可中断:
R提供了一种能够中断等待所的线程的机制,通过lock.lockInterruptibly()来实现这个机制公平锁:
R可以指定是公平锁还是非公平锁,默认是非公平锁选择性通知:
s与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制
关于选择性通知,ReentrantLock也可以实现,通过Conditoin实现,Condition是JDK1.5过后出现的。可以实现多路通知功能,也就是在一个Lock对象中可以创建多个Condition实例——对象监视器 线程对象可以注册在指定了Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。
ThreadLocal
后续再补……
线程池
顾名思义,池化思想。当有任务要处理的时候,直接从池子里面拿线程来执行任务。执行完了过后不会被立即销毁,继续等待后续任务的执行。
所谓的池化技术——线程池、数据库连接池、http连接池等等都是这个思想的应用。主要是为了减少每次获取资源的小号,提高对资源的利用率
降低资源的消耗:重复利用线程,不用反复的创建和销毁
提高响应速度:等到任务来的时候,不需要等待线程创建的时间,立即执行
提高线程的可管理性:有池子统一分配和管理
创建
方式一:推荐通过ThreadPoolExecutor构造函数来创建
方式二:不推荐通过Executors来创建
原因:通过这个工具来来创建
FixThreadPool和SingleThreadExecutor:使用的是无界阻塞队列的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,所以会堆积大量的请求,从而导致OOM
CachedThreadPool:使用的是同步队列SynchronousQueue,允许创建的线程数同样是Integer.MAX_VALUE,会造成创建大量的线程,导致OOM
ScheduledThreadPool和SingleThreadScheduledExecutor:使用的是无界的延迟阻塞队列,任务队列最大为Integer.MAX_VALUE导致OOM
七大参数
corePoolSize:最大可以同时运行的线程数量
maximumPoolSize:当存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程的线程数
workQueue:当任务来的时候先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被先存放到该队列中
keepAliveTime:闲置线程的最大存活时间
unit:keepAliveTime的单位
threadFactory:池子中创建线程所使用的工厂类
handler:饱和策略/拒绝策略
处理任务的流程
如果当前线程数 < corePoolSize,则创建新线程执行任务
如果当前线程数 >= corePoolSize,但是 < maximumPoolSize,就会吧任务丢进workQueue
如果任务丢不进workQueue(任务队列满了),同时当前线程数 < maximumPoolSize,则创建新线程执行任务
如果上述条件都难以满足:当前线程数快满了,任务队列也满了。这个时候就会执行拒绝策略
你会如何设定线程池大小
首先我觉得中国人嘛,从古至今都是遵守的中庸之道。就类比于现实世界中人们通过合作做某件事情的时候,人数肯定是不要过多或者过小,合适才是最好的。
如果设置的线程池数量过小的话,假设同一时间有大量的请求需要处理,就会导致大量的请求在workQueue里面排队等待执行,甚至会出现任务队列满了过后请求无法处理,或者是大量的请求堆积在workQueue,导致OOM。CPU根本没有充分利用到
如果设置的线程池数量过大的话,大量的线程可以会同时在争取CPU的资源,到只大量的上下文切换,影响整体执行效率
上下文切换:
就是说CPU为了让多个线程都能够有效的执行,它会为每个线分配时间片并轮询。然后当前任务在执行完CPU时间片切换到另一个任务之前会先保存自己的状态,以便下次在切换回这个任务的时候可以直接加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换
回到问题本身:
需要先判断任务是CPU密集(计算密集)任务还是IO密集任务
如果是CPU密集任务,这种任务主要是消耗CPU资源,所以只需要设置N+1就行了
如果是IO密集任务,这种任务可以多配置一些线程,因为线程在处理IO的时间段内是不占用CPU的,设置2N就可以
AQS(AbstractQueuedSynchronizer)
TODO 真吉尔🐔多,后续再补
AQS即抽象队列同步器,它其实就是一个通过维护一个线程队列(CLH)的一个抽象类,采用的是模板设计模式,父类将公共代码部分抽象出来,通过子类对其扩展进行不同类型的锁的实现(如:ReentrantLock、CountDownLatch、ReentrantReadWriteLock...)。而该CLH队列将每条将要去抢占资源的线程封装成一个Node节点来实现锁的分配,有一个int类变量表示持有锁的状态(private volatile int state),通过CAS完成对status值的修改(0表示没有,1表示阻塞)
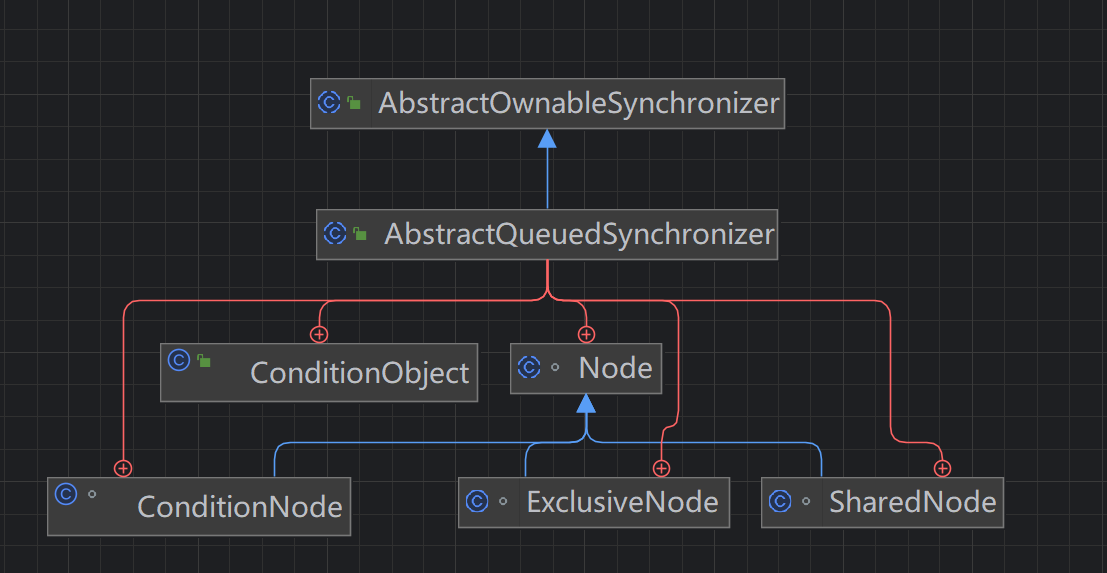
通过Node节点维护一个双向链表,其中子类又有独占节点、共享节点、条件节点(作为标识类)

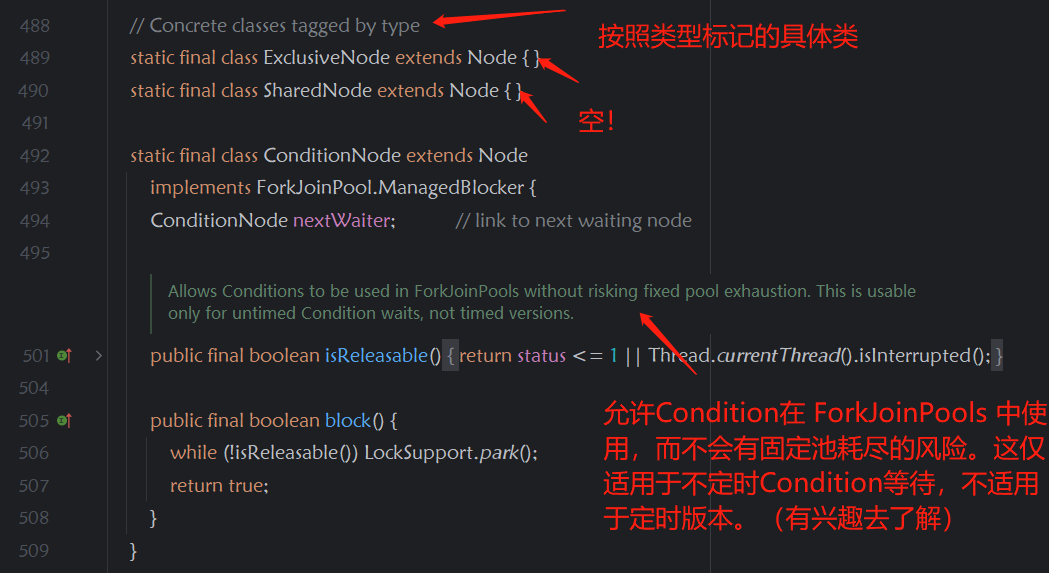
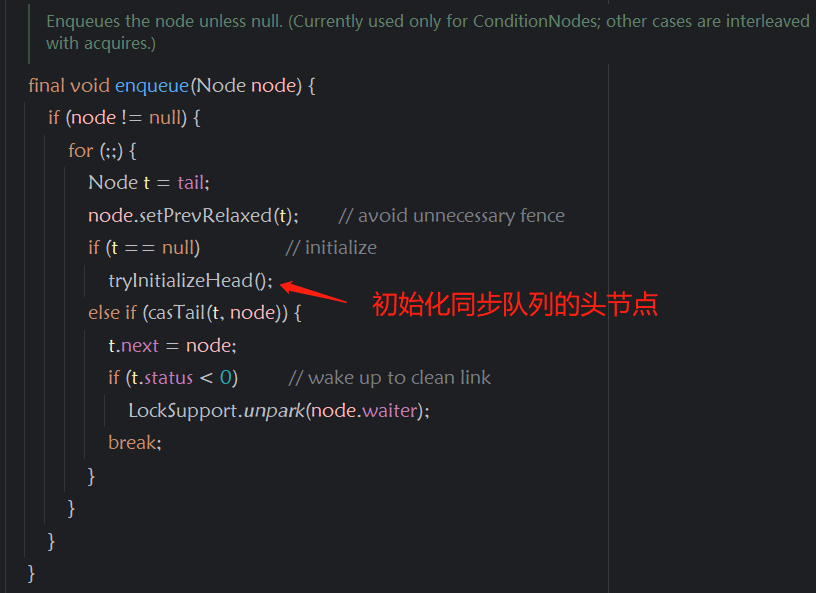
在代码中的使用:当有线程占用锁时,后面的线程开始进入队列,队列采用来加载的方式,当有线程需要排队时,开始初始化队列
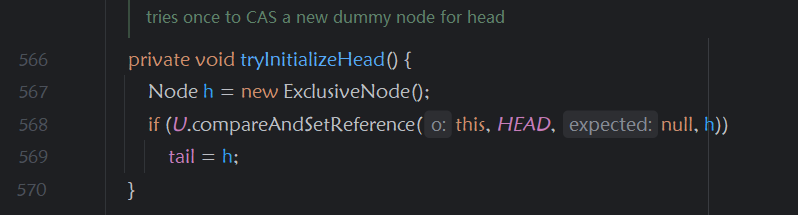
该独占节点主要用于区别于共享节点,用于共享节点实现自己的逻辑
通过ReentrantLock了解AQS
//todo
自我介绍
(技术面)
面试官你好,我叫杨晨,目前就读于重庆邮电大学软件工程专业,现在是大二。我是从大一入学的时候接触的Java
(HR面)
心识宇宙——上海
竹云科技——广州
运去哪——上海
悬镜——北京
元启星辰——北京
北京特征曲线——北京
浙江省北大信息技术高等研究院——杭州
维纳——成都
同程旅行——苏州
奔步——广州
复深蓝——上海
畅风通信——武汉
凯易迅——南京
上海鸿笛——杭州
浙江中控技术——杭州
山东依智——杭州
Last updated